9 Cluster randomised trials
For the trials we’ve been studying so far, the intervention is applied at an individual level. For many treatments this is realistic, for example a medicine, injection or operation. However, for some treatments this is not practical. One example would be implementing a new cleaning regime in operating theatres. It would be almost impossible to implement this if different patients within the same hospital would be allocated to different cleaning styles. Logistically it would be very difficult, and there would likely be contamination as staff may be reluctant to clean an operating theatre in what might now seem an inferior way, for a control participant. In general it is very difficult (if not impossible) to implement changes in practice across healthcare systems at an individual level.
The solution to this is to work at the group level, rather than the individual level.
9.1 What is a cluster RCT?
In a cluster RCT, participants within the same natural group (e.g.. doctor’s surgery, hospital, school, classroom,…) are all allocated to the same group together. This means that, in the cleaning example above, the staff at a hospital in the treatment group can be trained in the new practice, all patients at that hospital will ‘receive the new treatment’, and contamination between groups is minimised.
The main issue that makes cluster RCTs different is that participants within the same group are often likely to be more similar to one another than to participants from a different group. We expect that each group has its own ‘true’ mean \(\mu_k\) , which is different from the underlying population mean \(\mu\), and that the cluster means are distributed with mean \(\mu\) and variance \(\sigma^2_b\) (more on \(\sigma^2_b\) soon). This violates one of the key assumptions we’ve held so far, that the data are independent, and leads us to a very important quantity called the intracluster correlation (ICC).
9.1.1 Intracluster correlation
The ICC quantifies the relatedness of data that are clustered in groups by comparing the variance within groups to the variance between groups. The ICC is given by
\[ICC = \frac{\sigma^2_b}{\sigma^2_b + \sigma^2_w}, \] where \(\sigma^2_b\) is the variance between groups and \(\sigma^2_w\) is the variance within groups. At one extreme, where \(\sigma_w^2=0\), we have \(ICC=1\) and all measurements within each group are the same. At the other extreme, where \(\sigma^2_b=0\), \(ICC=0\) and in fact all groups are independent and identically distributed.
We can estimate \(\sigma_w^2\) and \(\sigma_b^2\) using \(s_w^2\) and \(s_b^2\), which we find by decomposing the pooled variance. Here, \(g\) is the number of groups, \(n_j\) is the number of participants in group \(j\) and \(n\) is the total number of participants.
\[ s^2_{Tot} = \frac{\sum\limits_{j=1}^g \sum\limits_{i=1}^{n_j}\left(x_{ij}-\bar{x}\right)^2}{n-g}\\ \] We can split this up as
\[ \begin{aligned} s^2_{Tot} & = \frac{1}{n-g}\sum\limits_{j=1}^g \sum\limits_{i=1}^{n_j}\left(x_{ij} - \bar{x}_j + \bar{x}_j-\bar{x}\right)^2\\ & = \frac{1}{n-g}\sum\limits_{j=1}^g \sum\limits_{i=1}^{n_j}\left[\left(x_{ij} - \bar{x}_j\right)^2 + \left(\bar{x}_j-\bar{x}\right)^2 + 2\left(x_{ij} - \bar{x}_j\right)\left(\bar{x}_j-\bar{x}\right)\right]\\ & = \frac{1}{n-g}\sum\limits_{j=1}^g \sum\limits_{i=1}^{n_j}\left[\left(x_{ij} - \bar{x}_j\right)^2 + \left(\bar{x}_j-\bar{x}\right)^2 \right]\\ &= \underbrace{\frac{1}{n-g}\sum\limits_{j=1}^g \sum\limits_{i=1}^{n_j}\left(x_{ij} - \bar{x}_j\right)^2}_{\text{Within groups}} + \underbrace{\frac{1}{n-g}\sum\limits_{j=1}^g n_j\left(\bar{x}_j - \bar{x}\right)^2}_{\text{Between groups}} \end{aligned} \]
Example 9.1 We will demonstrate the ICC using a dataset that has nothing to do with clinical trials. The cheese dataset contains the price per unit and volume of sales of cheese (who knows what kind) at many Kroger stores in the US. We also know which city the Krogers are in, and we have data for 706 stores across 11 cities. It might be reasonable to expect that if we have information about the price and volume for several stores within a particular city, this gives us more information about the price and volume for another store in that same city than for a store in another city. Figure 9.1 shows the price and volume for all stores, coloured by city.
cheese = read.csv("kroger.csv", header=T)
cheese$city = as.factor(cheese$city)
ggplot(data=cheese, aes(x=price, y=vol, col=city)) + geom_point()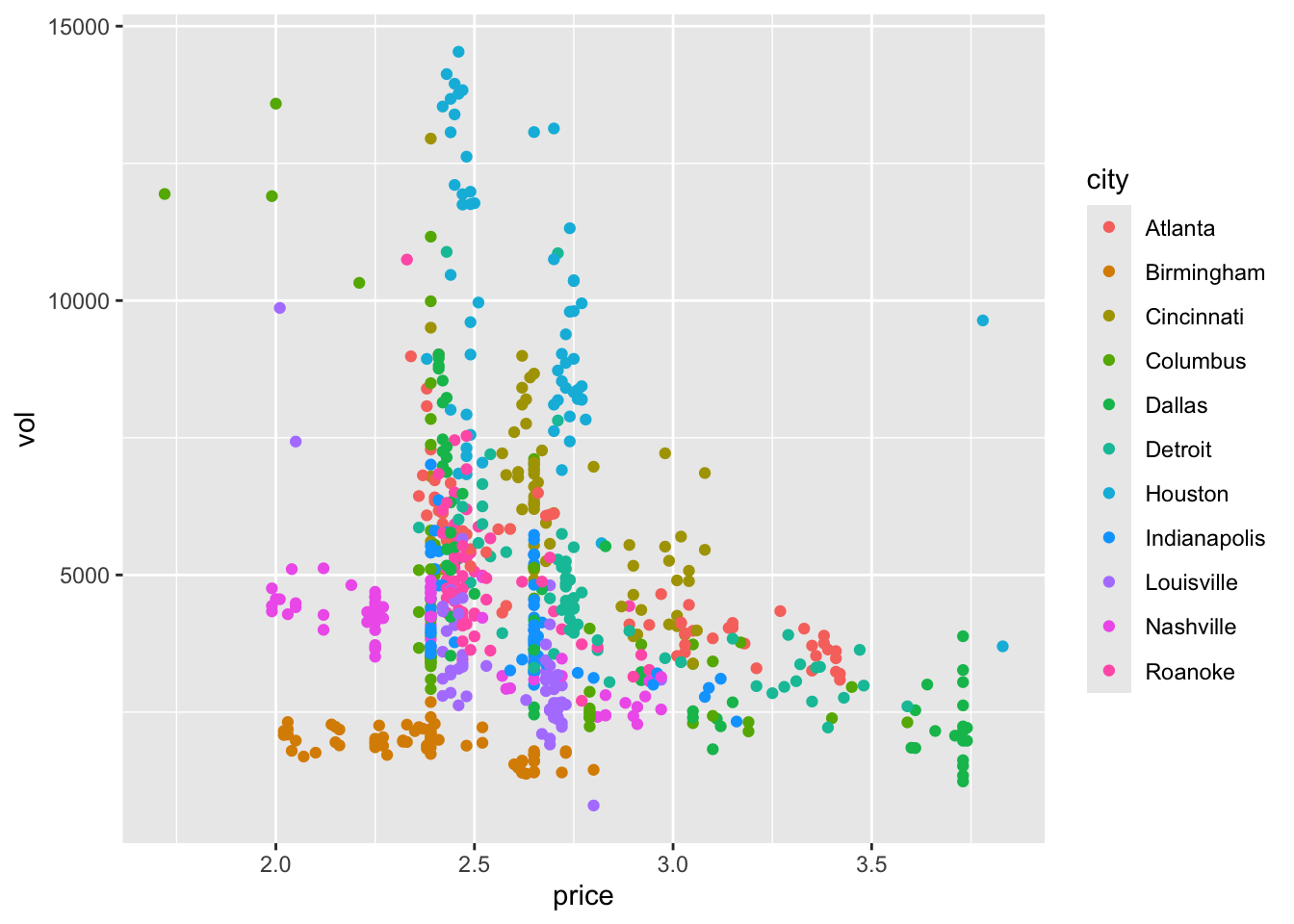
Figure 9.1: Price per unit and volume of sales of cheese for 706 Kroger stores.
To calculate the ICC we define two functions, between.var and within.var, to calculate the between group and within group variance, as explained above.
Click to show R functions
# Firstly we define functions for the estimates
between.var = function(
data,
groupvec
){
groups = levels(as.factor(groupvec))
ng = length(groups)
ntot = length(data)
means = sapply(1:ng, function(i){mean(data[groupvec == groups[i]])})
njvec = sapply(1:ng, function(i){length(data[groupvec == groups[i]])})
mean = mean(data)
ssqvec = sapply(1:ng, function(i){(njvec[i]*(means[i]-mean)^2)})
sum(ssqvec)/(ntot-ng)
}
within.var = function(
data,
groupvec
){
groups = levels(as.factor(groupvec))
ng = length(groups)
ntot = length(data)
means = sapply(1:ng, function(i){mean(data[groupvec == groups[i]])})
njvec = sapply(1:ng, function(i){length(data[groupvec == groups[i]])})
g_sums = rep(NA, ng)
for (j in 1:ng){
data_j = data[groupvec == groups[j]]
ssqvec = rep(NA, njvec[j])
for (i in 1:njvec[j]){
ssqvec[i] = (data_j[i] - means[j])^2
}
g_sums[j] = sum(ssqvec)/(ntot - ng)
}
sum(g_sums)
}## [1] 0.08860193## [1] 0.03002494## [1] 0.253104If we had to predict the price of cheese in a new city, all we can say is we expect the mean \(\mu_{g+1}\) to come from \(N\left(\mu,\;\sigma^2_b\right)\), where \(\mu\) is the mean price of cheese in the overall population and \(\sigma^2_b\) is the between group variance, and the individual cheese prices to come from \(N\left(\mu_{g+1},\,\sigma^2_w\right)\).
## [1] 2.641317Estimating the ICC when planning a study is an important step, but isn’t always easy. For a well-understood (or at least well-documented) condition, it can often be estimated from existing data, which is likely to cover many sites. In non-medical studies like education or social interventions (where cluster RCTs are very common), it can be much more difficult because there is generally less data. Statistical studies are much newer in these areas, though they are becoming increasingly common, and even mandated by some organisations (for example the Educational Endowment Foundation).
9.2 Sample size
The upshot of the non-independence of the sample is that we have less information from \(n\) participants in a cluster RCT than we would do for an individual-based RCT where all the participants were independent (at least conditional on some covariates).
At one extreme, where ICC=0, there is in fact no intracluster correlation, all the groups have the same mean, and this is the same as a normal RCT. At the other extreme, where ICC=1, all measurements within a cluster are identical, and to achieve the same power as with \(n\) participants in a standard RCT, we would need \(n\) clusters (and their size would be irrelevant). Obviously neither of these is ever true! In most studies, the ICC is in \(\left(0,\;0.15\right)\).
We will consider the sample size (and indeed most other things) for a cluster RCT in which the outcome is continuous (as in Chapter 2), but you can equally do a cluster RCT with a binary or time-to-event outcome.
The first step is to think about how the clustering affects the variance of the sample mean for either group. An estimate of the outcome variance in the control group, ignoring the clustering, is
\[\begin{equation} \hat{\sigma}^2 = \frac{\sum\limits_{j=1}^g\sum\limits_{i=1}^{n_j}\left(X_{ij} - \bar{X}\right)^2}{n-1}, \tag{9.1} \end{equation}\]
where as before there are \(g\) clusters, cluster \(j\) has size \(n_j\) and \(\sum\limits_{j=1}^gn_j=n\) is the total sample size.
The mean is also calculated without reference to the clustering, so
\[\bar{X} = \frac{\sum\limits_{j=1}^g\sum\limits_{i=1}^{n_j}X_{ij}}{n}.\]
It can be shown that the variance of the overall mean in either group is inflated by a factor of
\[1 + \rho_{ICC}\left[ \frac{\sum\limits_j n_j^2}{N} - 1 \right], \] where \(\rho_{ICC}\) is the intracluster correlation.
This quantity is known as the design effect. Notice that if all the groups are the same size \(n_g = \frac{n}{g}\) then the design effect simplifies to
\[1 + \rho_{ICC}\left(n_g - 1\right).\] We will assume from now on that this is the case.
9.2.1 A formula for sample size
Now that we know \(\operatorname{E}\left(\hat{\sigma}^2\right)\) we can adapt our sample size formula from Section 2.5. For an individual-level RCT with a continuous outcome, and assuming an unpaired, two-sided t-test comparing the outcomes, we had
\[\begin{equation} n = \frac{2\sigma^2\left(z_{\beta} + z_{\alpha/2}\right)^2}{\tau^2_M}, \tag{9.2} \end{equation}\]
and the reason we were able to do this was because the variance of the treatment effect estimate was \(\sigma^2/n\). For a cluster RCT, the variance of the treatment effect under the same model assumptions is
\[\begin{equation} \frac{\sigma^2}{n} \left[1 + \rho_{ICC}\left(\frac{\sum\limits_{j=1}^g n_j}{n}-1\right)\right] \tag{9.3} \end{equation}\]
At the planning stage of a cluster RCT we are unlikely to know the size of each cluster; each individual involved will usually need to give their consent, so knowing the size of the hospital / GP surgery / class is not enough. Instead, usually a [conservative] average cluster size \(n_g\) is specified, and this is used. In this case, the variance of the treatment effect in Equation (9.3) becomes
\[\begin{equation} \frac{\sigma^2}{n} \left[1 + \rho_{ICC}\left(n_g-1\right)\right] . \tag{9.4} \end{equation}\]
Equation (9.4) can be combined with Equation (9.2) to give the sample size formula for a cluster RCT:
\[n = \frac{2\sigma^2\left[1 + \rho_{ICC}\left(n_g-1\right)\right]\left(z_{\beta} + z_{\alpha/2}\right)^2}{\tau^2_M}. \] Since \(n=n_gg\), this can be rearranged to find the number of clusters of a given size needed, or the size of cluster if a given number of clusters is to be used.
The sample size (and therefore the real power of the study) depends on two additional quantities that are generally beyond our control, and possibly knowledge: \(\rho_{ICC}\) and \(n_g\). It is therefore sensible to conduct some sensitivity analysis, with several scenarios of \(\rho_{ICC}\) and \(n_g\), to see what the implications are for the power of the study if things don’t quite go to plan.
Example 9.2 This is something I wrote for an education study I’m involved in (funded by the EEF) where the treatment is a particular way of engaging 2 year olds in conversation. The outcome variable is each child’s score on the British Picture Vocabulary Scale (BPVS), a test aimed at 3 - 16 year olds designed to assess each child’s vocabulary. We needed to recruit some number of nurseries, but had very little information about the ICC (notice that the age in our study is outside the intended range of the BPVS test!).
To help the rest of the evaluation team understand the sensitivity of the power of the study to various quantities, I designed this dashboard, so that they could play around with the variables and see the effect.
As well as giving the sample size for a simple t-test (as we’ve done above) it also shows the size for a random effects model (similar to ANCOVA, more on this soon), which is why the baseline-outcome correlation (about which we also know very little) is included.
The plot shows the minimum detectable effect size (MDES, or \(\tau_M\), in SD units), since the evaluation team wanted to know what size of effect we could find with our desired power.
9.3 Allocation
In a cluster RCT, everyone within a particular cluster will be in the same group (\(T\) or \(C\)). Therefore, the allocation needs to be performed at the cluster level, rather than at the individual level as we did in Chapter 3.
In theory we could use any of the first few methods we learned (simple random sampling, random permuted blocks, biased coin, urn design) to allocate the clusters. However, there are often relatively few clusters, and so the potential for imbalance in terms of the nature of the clusters would be rather high. This means we are more likely to use a stratified method or minimisation.
In terms of prognostic factors, there are now two levels: cluster level and individual level. For example, in a study with GP practices as clusters, some cluster-level covariates could be the size of the practice, whether it was rural or urban, the IMD (index of multiple deprivation) of the area it was in. It would be sensible to make sure there was balance in each of these in the allocation. One might also include aggregates of individual-level characteristics, for example the mean age, or the proportion of people with a particular condition (especially if the study relates to a particular condition).
However, a key feature of cluster RCTs means that in fact some different, and perhaps more effective, allocation methods are open to us.
9.3.1 Allocating everyone at once
The methods we’ve covered so far assume that participants are recruited sequentially, and begin the intervention at different points in time. In this scenario, when a particular participant (participant \(n\)) is allocated we only know the allocation for the previous \(n-1\) participants. It is very likely that we don’t know the details of the following participants, in particular their values of any prognostic variables. This makes sense in many medical settings, where a patient would want to begin treatment as soon as possible, and there may be a limited number of patients with particular criteria at any one time.
However, cluster RCTs rarely deal with urgent conditions (at least in the sense of administering a direct treatment), and so the procedure is usually that the settings (the clusters) are recruited over some recruitment period and all begin the intervention at the same time. This means that at the point of allocation, the details of all settings involved are known. There are a couple of proposals for how to deal with allocation in this scenario, and we will look at one now.
9.3.2 Covariate constrained randomization
This method is proposed in Dickinson et al. (2015), and implemented in the R package cvcrand. We’ll review the key points of the method, but if you’re interested you can find the details in the article.
Baseline information must be available for all settings, for any covariate thought to be potentially important. These can be setting-level variables or aggregates of individual-level variables. Once all this data has been collected, the randomisation procedure is as follows.
Firstly, generate all possible allocations of the clusters into two arms (\(T\) and \(C\)).
Secondly, rule out all allocations that don’t achieve the desired balance criteria.
For a categorical covariate, the procedure is very simple. For example, we may stipulate that we want groups \(T\) and \(C\) to have the same number of rural GP practices as one another. In this case, we would remove from our set of possible allocations any where the number was different, or perhaps where it differed by more than some number \(d_{rural}\). We continue for all the covariates we want to balance, setting rules for each one.
Continuous covariates are standardized and used to calculate a ‘balance score’ \(B\) for each of the remaining allocations. A cut-off is used to rule out all allocations that don’t achieve the desired level of balance. This leaves an ‘optimal set’ of allocations.
Finally, an allocation is chosen at random from the optimal set, and this is the allocation that is used.
9.4 Analysing a cluster RCT
As with the other stages of a cluster RCT, to conduct an effective and accurate analysis we need to take into account the clustered nature of the data. There are several ways to do this, and we will whizz through the main ones now.
Example 9.3 The data we use will be from an educational trial, contained in crtData in the package eefAnalytics, shown in Figure 9.2 . The dataset contains 22 schools and 265 pupils in total. Each school was assigned to either 1 (group \(T\)) or 0 (group \(C\)). Each pupil took a test before the trial, and again at the end of the trial. We also know the percentage attendance for each pupil. We will use this data to demonstrate each method.
## 'data.frame': 265 obs. of 4 variables:
## $ School : Factor w/ 22 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Posttest : num 16 13 18 14 25 13 23 26 16 8 ...
## $ Intervention: Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 2 2 2 ...
## $ Prettest : num 1 4 5 4 5 2 5 5 2 2 ...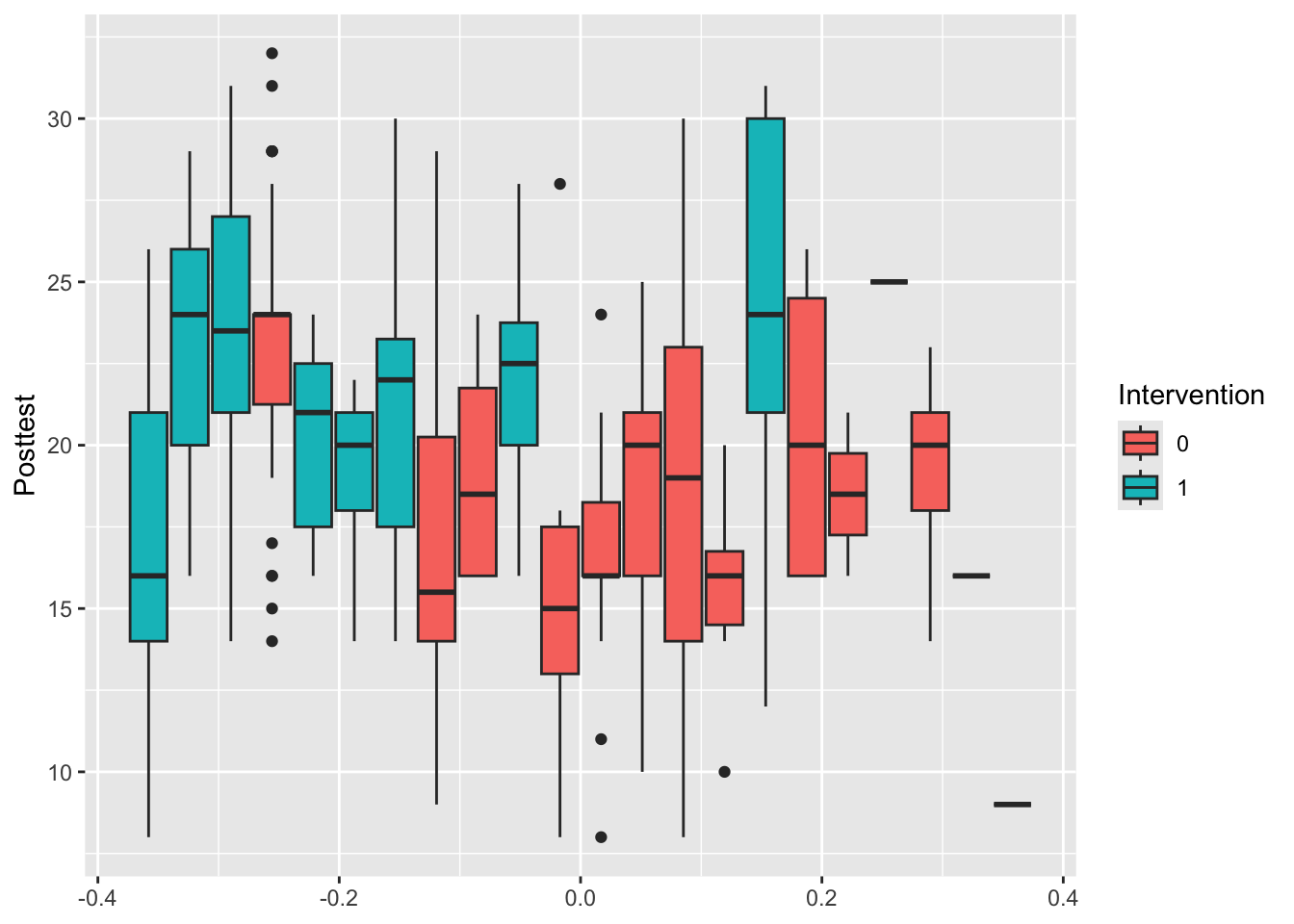
Figure 9.2: Box plots of the outcome Posttest for each school, coloured by Intervention.
9.4.1 At the cluster level
In cluster level analysis, the data are aggregated to the cluster level, so that for each cluster (school, in our case), there is effectively one data point. The advantage of this approach is that, because the design is conducted at the cluster level, the statistical methodology is relatively simple - for example, a t-test. However, if cluster sizes vary a lot, a cluster-level analysis is often not appropriate because they usually rely on the assumption that the variance of the outcome in each cluster is approximately the same. As we have seen, the larger a group, the smaller the variance of its sample mean. There are methods designed to account for this, such as the weighted t-test, but these methods are generally inefficient and less robust. These methods are generally thought to be appropriate for fewer than 15-20 clusters per treatment arm.
One possibility for our trial would be to collect the mean and SD of scores within each school, and perform a t-test to find out if there is a significant difference between the intervention and control arms. If we wanted to find out whether this depended on, say, gender, we could split the data set and perform separate t-tests for the different gender groups. This has the advantage that it is simple to implement, but the disadvantage that it is difficult to take into account covariates (apart from in the simple way discussed for eg. gender). With a small study, it is likely that there is some imbalance in the design in terms of covariates.
The required sample size for this option would be
\[ g = \frac{2 \sigma^2 \left[1+ \left(n_g-1\right)\rho_{ICC}\right]}{n_g\tau^2_M}\left(z_{\beta} + z_{\frac{1}{2}\alpha}\right)^2, \] where \(n_g\) is the average cluster size and \(g\) is the number of clusters per treatment arm. This is the value we worked out in Section 9.2.1
Example 9.4 We can perform this analysis on our schools data. The first step is to calculate the difference between posttest and pretest for each pupil.
We can then aggregate this to find the mean of diff for each school, shown in Table 9.1:
| School | MeanDiff | ng | Group |
|---|---|---|---|
| 1 | 13.76923 | 13 | 1 |
| 2 | 19.09091 | 33 | 1 |
| 3 | 20.43333 | 30 | 1 |
| 4 | 19.00000 | 30 | 0 |
| 5 | 16.66667 | 15 | 1 |
| 6 | 14.40000 | 5 | 1 |
| 7 | 16.75000 | 24 | 1 |
| 8 | 13.83333 | 12 | 0 |
| 9 | 15.00000 | 4 | 0 |
| 10 | 18.28571 | 14 | 1 |
We can also visualise the mean differences by group
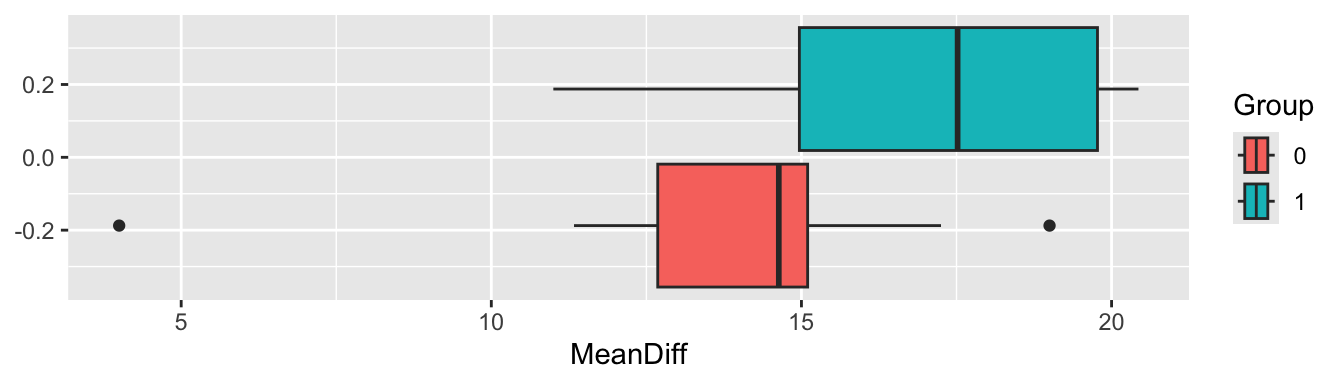
Figure 9.3: Boxplots of the mean differences for each trial arm
From Figure 9.3 it certainly looks likely that a significant difference will be found.
t.test(
x=crt_summ$MeanDiff[crt_summ$Group==0],
y=crt_summ$MeanDiff[crt_summ$Group==1],
alternative = "two.sided",
paired = F,
var.equal=F
)##
## Welch Two Sample t-test
##
## data: crt_summ$MeanDiff[crt_summ$Group == 0] and crt_summ$MeanDiff[crt_summ$Group == 1]
## t = -2.2671, df = 19.983, p-value = 0.03463
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -6.4133879 -0.2667059
## sample estimates:
## mean of x mean of y
## 13.72454 17.06459This is fairly easy to implement, but it seems rather unsatisfactory. It’s also probably not entirely appropriate because the group sizes vary from one (!) to 33. What we need is a linear (in the continuous outcome case at least) model that takes into account the covariates, and makes the most of the available data.
9.4.2 At the individual level: mixed effects models
Perhaps the prevalent way of analysing the data from cluster randomized trials is the mixed effects model or random effects model, or multilevel model. In basic terms, mixed effects models are used whenever it cannot be assumed that the outputs are all independent of one another. In the cluster randomized trial setting, this is because outcomes for participants within the same cluster can be expected to be more highly correlated than outcomes for patients from different clusters, but we will see examples of other designs in the next chapter.
To understand mixed effects models, we need to think about the difference between fixed effects and random effects, in particular for categorical/factor variables.
Fixed effects
These are the sorts of factor variables we’re used to dealing with in linear models: we don’t assume any relationship between the levels, and we are generally interested in comparing the groups or categories represented by the fixed effect factors. We’ve seen these throughout the course, most notably with the treatment group variable \(G_i\), but also with things like smoking history, sex, disease details. When conducting a clinical trial, we’re likely to try to include participants with all levels of the fixed effects we’re interested in, so that we can make inferences about the effect of the different levels of those effects. For example, we might want a good balance of male and female participants, so that we can understand the effect of the treatment on both groups.
Random effects
Random effects are probably just as common in real life, but we haven’t seen them yet. These are factor variables that we think of as being drawn from some underlying model or distribution. For example, this could be GP surgery or school class, or an individual. We expect each GP surgery / school class / individual to behave slightly differently (depending on the extent of the intracluster correlation) but to behave as though from some overall distribution. Unlike fixed effects, random effects are generally things we aren’t specifically interested in understanding the effect of, but we want to account for the variation they bring. We’re also unable to include all levels of the random effect in our study - for example, a study looking at the effect of an intervention in schools will involve perhaps 50 schools, but we want to apply to results to all schools in the UK (say). We therefore assume that the schools are drawn from some normal distribution (in terms of the outcome we’re interested in), and that therefore all the schools we haven’t included also belong to this distribution. In Example 9.1 we aren’t trying to compare different cities, and we certainly don’t have data for Kroger stores in all cities, but we’re assuming that the mean cheese price \(\mu_{\text{city}_i}\) in the different cities is drawn from \(N\left(\mu,\,\sigma^2_B\right)\), and that within each city the cheese price is drawn from \(N\left(\mu_{\text{city}_i},\;\sigma^2_W\right)\).
Including random effects allows us to account for the fact that some schools might be in general a bit better / worse performing, or some individuals might be a bit more / less healthy, because of natural variation. We will see more examples of the use of random effects in the next chapter
The mixed effects model
Mixed effects models allow us to combine fixed effects and random effects. They are useful for many more situations than cluster RCTs, but this is as good a place as any to start!
The mixed effects model takes the form
\[\begin{equation} x_{jk} = \alpha + \beta G_j + \sum\limits_l \gamma_l z_{jkl} + u_{j} + v_{jk} \tag{9.5} \end{equation}\]
where
- \(x_{jk}\) is the outcome for the \(k\)-th individual in the \(j\)-th cluster
- \(\alpha\) is the intercept of the model
- \(\beta\) is the intervention effect, and \(G_j\) the group indicator variable (0 for group \(C\), 1 for group \(T\)). Our null hypothesis is that \(\beta\) is also zero)
- The \(z_{jkl}\) are \(L\) different individual level covariates that we wish to take into account, and the \(\gamma_l\) are the estimated coefficients.
- \(u_{j}\) is a random effect relating to the \(j\)-th cluster. This is the term that accounts for the between-cluster variation. We assume \(u_{j}\) is normally distributed with mean 0 and variance \(\sigma^2_B\) (the between-cluster variance).
- \(v_{jk}\) is a random effect relating to the \(k\)-th individual in the \(j\)-th cluster (ie. an individual level random error term), assumed normally distributed with mean 0 and variance \(\sigma^2_W\) (the within-cluster variance).
The part of the model that makes this particularly suitable to a cluster randomized trial is \(u_{j}\). Notice that this has no \(k\) index, and is therefore the same for all participants within a particular cluster.
With a random effects model we can take into account the effects of individual-level covariates and also the clustered design of the data. Approximately, our sample size requirements are
\[ g = \frac{2 \sigma^2 \left[1+ \left(n_g-1\right)\rho_{ICC}\right]\left(1-\rho^2\right) }{n_g\tau^2_M}\left(z_{\beta} + z_{\frac{1}{2}\alpha}\right)^2. \]
Broadly this follows on from the logic we used to show the reduction in variance from the ANCOVA model in Section 4.3.1.2, and you’ll notice that the factor of \(1-\rho^2\) is the same. The details for cluster randomized trials are given in Teerenstra et al. (2012).
This is the ‘Random effects model’ line in the shiny dashboard.)
The random effects model is more suitable when there are more than around 15-20 clusters in each arm.
Example 9.5 We’ll now fit a random effects model to the crtData dataset from eefAnalytics. A good starting point is to plot the data with this in mind, to see what we might expect.
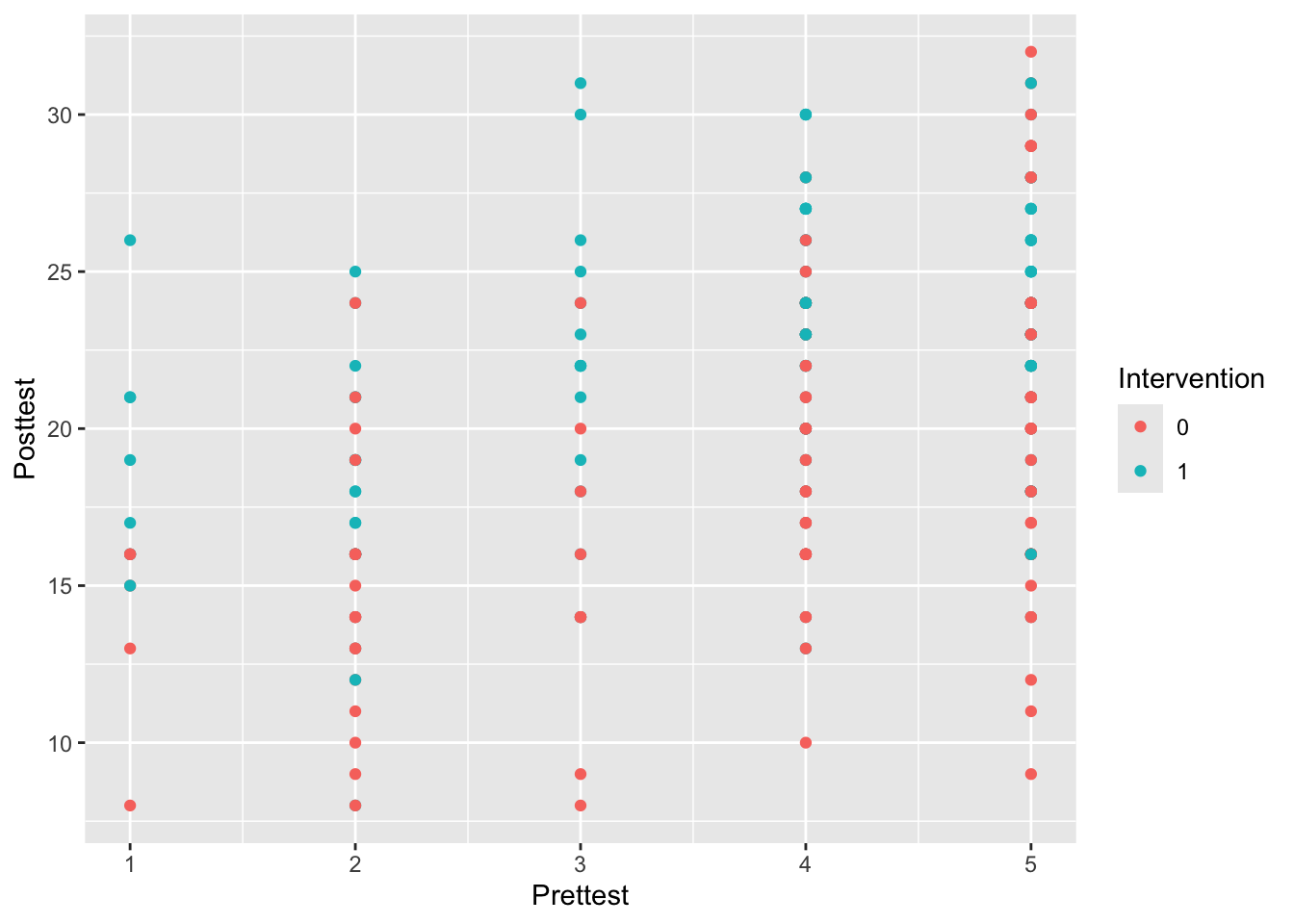
Figure 9.4: Posttest against Prettest, coloured by Intervention
From Figure 9.4 it appears there might be a positive relationship between Prettest and Posttest, and also that the Posttest scores might be higher in the intervention group.
We’ll do this using the R package lme4. The function to specify a linear mixed effects model is called lmer, and works very similarly to lm. The term (1|School) tells R that the variable School should be treated as a random effect, not a fixed effect.
library(lme4)
library(sjPlot)
lmer_eef1 = lmer(Posttest ~ Prettest + Intervention + (1|School), data=crt_df )
summary(lmer_eef1)## Linear mixed model fit by REML ['lmerMod']
## Formula: Posttest ~ Prettest + Intervention + (1 | School)
## Data: crt_df
##
## REML criterion at convergence: 1493.8
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.46249 -0.64166 0.01626 0.59655 2.60277
##
## Random effects:
## Groups Name Variance Std.Dev.
## School (Intercept) 5.674 2.382
## Residual 14.779 3.844
## Number of obs: 265, groups: School, 22
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 11.2286 1.1250 9.981
## Prettest 1.7889 0.2004 8.928
## Intervention1 3.1097 1.2094 2.571
##
## Correlation of Fixed Effects:
## (Intr) Prttst
## Prettest -0.681
## Interventn1 -0.493 -0.010The package sjPlot contains functions to work with mixed effect model objects, for example plot_model

Figure 9.5: CIs for the model coefficients
Perhaps unsurprisingly, the coefficient of the baseline test score is very significant, and the intervention also has a significant effect.
There are various different ways we can include random effects in the model, as shown in Figure 9.6. In our EEF data example we have used a fixed slope and random intercept.
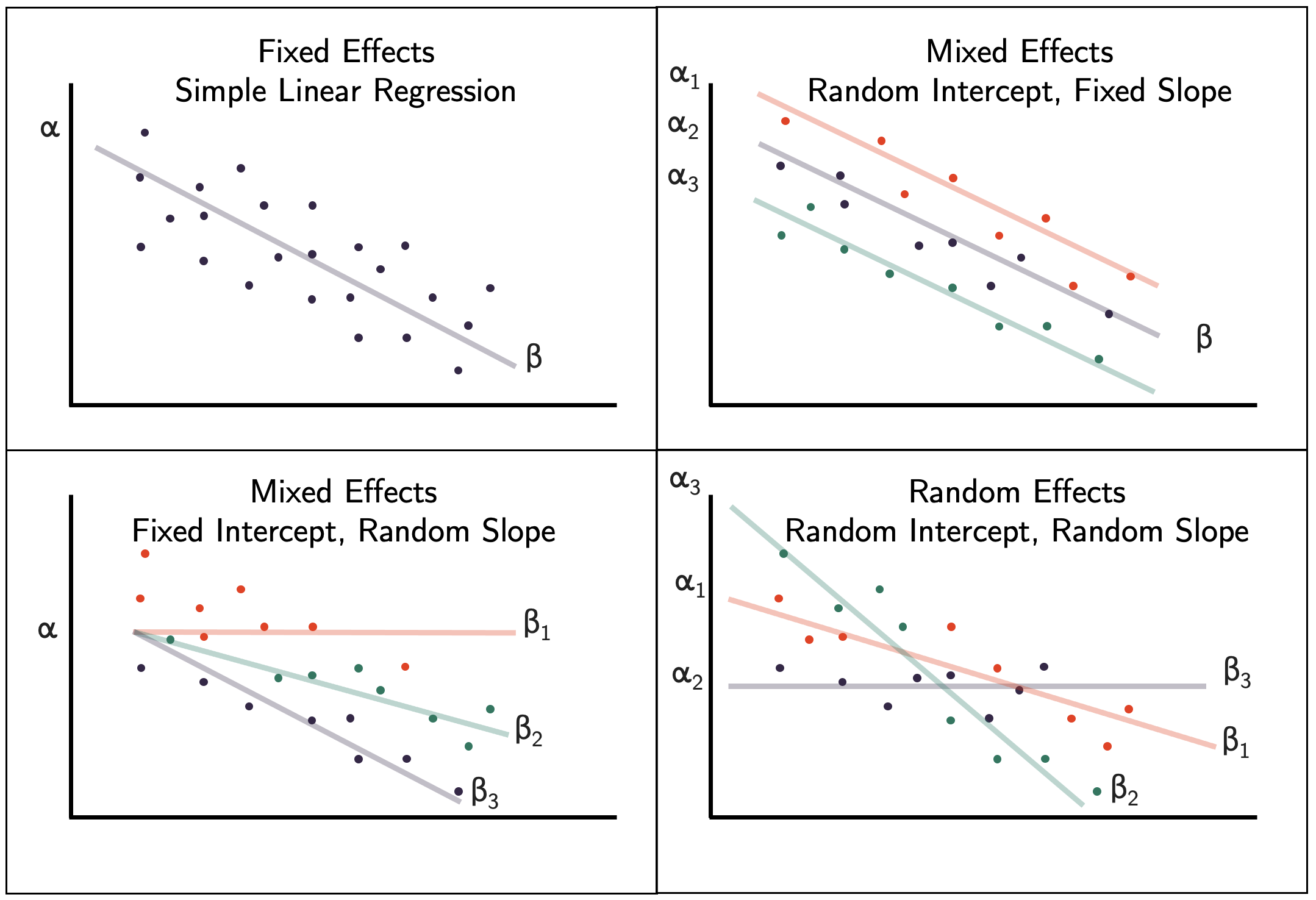
Figure 9.6: Different ways of including random effects in a mixed effects model.
The mixed effects model can be extended to a generalized mixed effects model, which is akin to a generalized linear model. For example, with a binary outcome \(X_{ijk}\) we can adopt the model
\[ \operatorname{logit}\left(\pi_{ijk}\right) = \alpha + \beta G_i + \sum\limits_l \gamma_l z_{ijkl} + u_{ij} + v_{ijk}. \]
The next section covers some more trial designs for which mixed effects models are useful.